業務改善・業務自動化を得意とするエンジニア
Python・Excel VBA・Google Apps Script・Microsoft Power Platform
現場業務を理解し、実際に使われる業務ツールや業務アプリを構築することを得意としています。
業務効率化・自動化の開発では、Python・Excel VBA・Google Apps Script・
Microsoft Power Platform を用い、自身で実装を行っています。
一方で、生成AIを用いた新しい開発手法の検証にも取り組んでおり、
設計・意思決定を人が担い、実装をAIに委ねる開発スタイルを
実証的に試すためのプロジェクトとして「RESYSTEM」「Goal Achiever」を開発しています。
スキルセット
■ 業務効率化・自動化(自分で実装)
- Python(業務自動化、データ処理、スクレイピング)
- Excel VBA(業務ツール作成)
- Google Apps Script(スプレッドシート連携、自動化)
- SQL(MySQL)
■ ローコード開発(自分で実装)
- Microsoft Power Platform(Power Apps,Power Pages,Power Automate)
■ 業務・開発支援ツール
- WordPress(構築・運用)
- GitHub(Privateリポジトリ)
- Backlog
- Trello
- Google広告 / Yahoo広告 / ストアマッチ広告 / 楽天RPP広告
- Xサーバー(共有サーバー / VPS)
- Google Workspace
- Microsoft365管理センター
■AIで開発(AIが実装)
- Laravel
- Next.js
- Flask
- PyQt5
- FFmpeg
- OpenCV
- PyTorch
- MySQL
- PostgreSQL
- SQLite
- Firebase
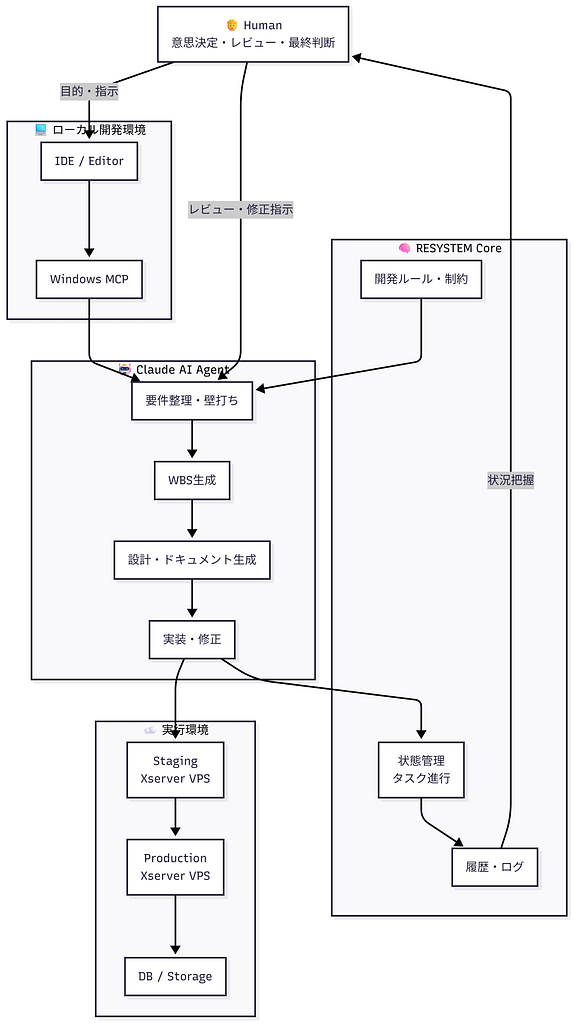
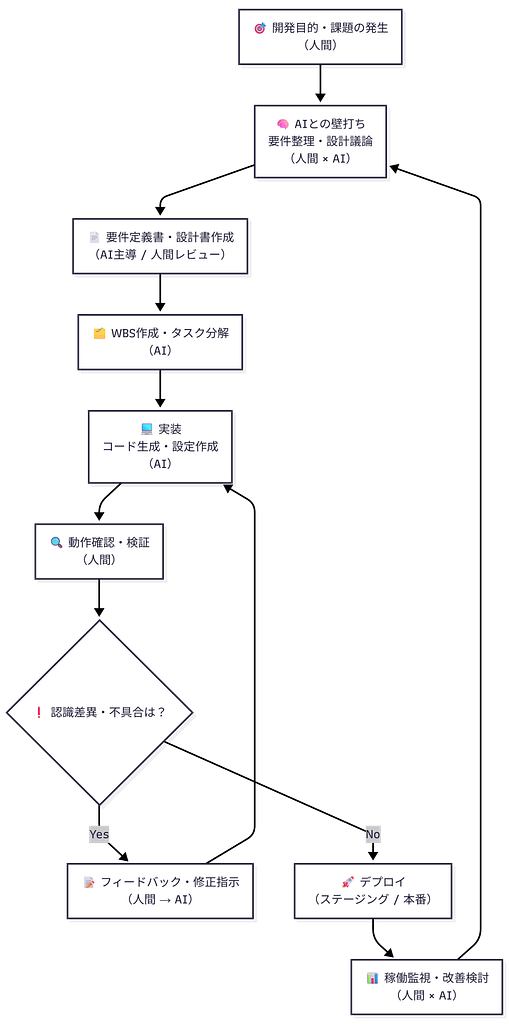
AI使用時の開発フロー
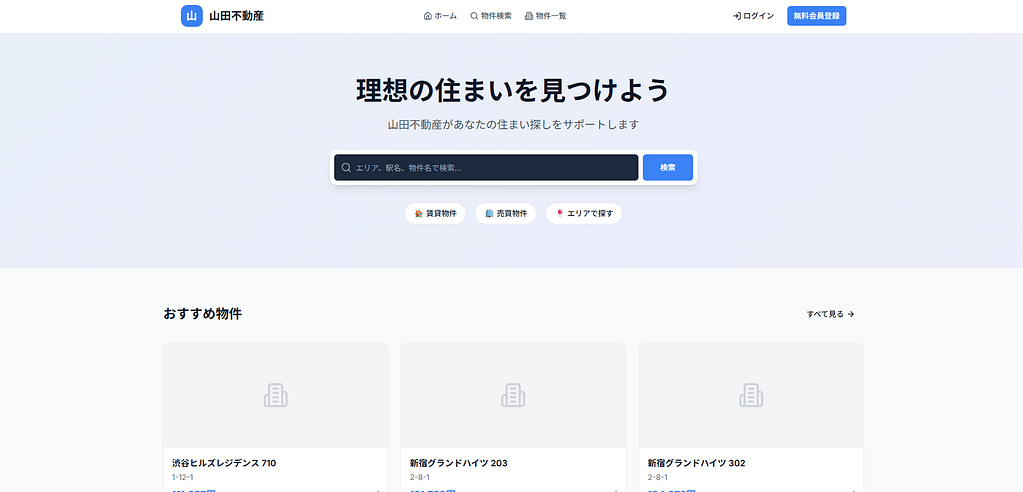
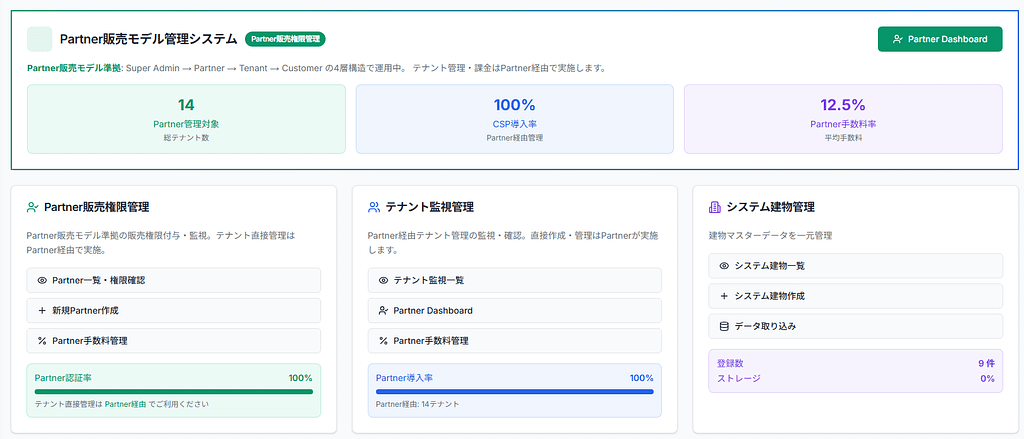
RESYSTEM
エンタープライズ級 不動産管理統合プラットフォーム
RE-Systemは、
私が「設計・実装・運用」すべてを行っている本番の様な環境で稼働中のWebシステムです。
※現在はPhase10まである内のPhase1部分のみ
概要
- 不動産管理業務を統合的に管理するSaaS型プラットフォーム
- 4つのポータルを1つのシステムとして統合
- マルチテナント対応・本番運用中
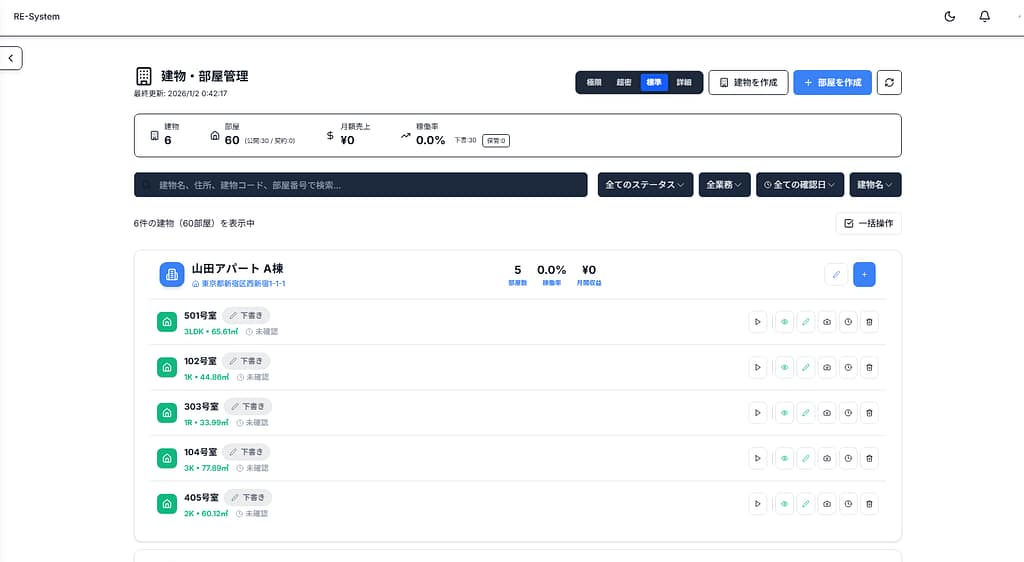
システム構成
- バックエンド:Laravel(API 280+ / 26モジュール)
- フロントエンド:Next.js(200+ページ)
- 本番 / ステージング / 開発環境を完全分離
4つのポータル
- Customer Portal(顧客向け)
- Tenant Admin(不動産事業者向け)
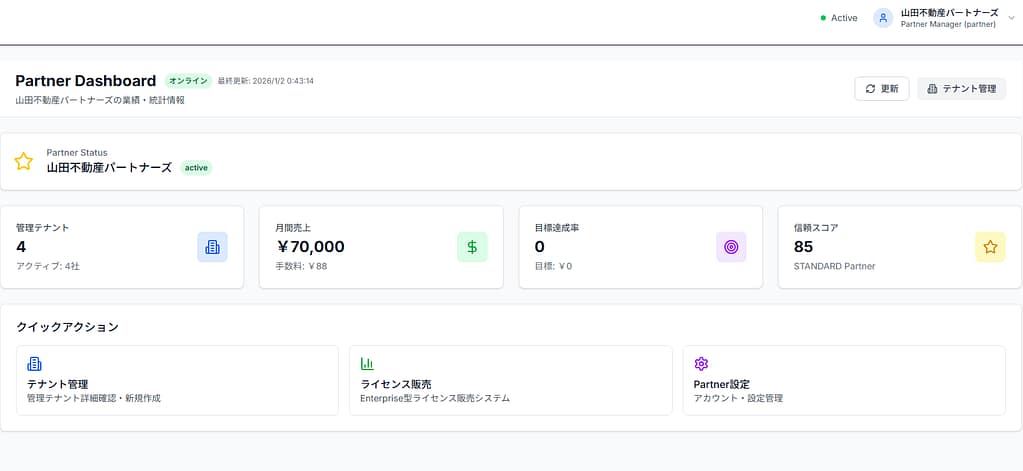
- Partner Portal(販売代理店向け)
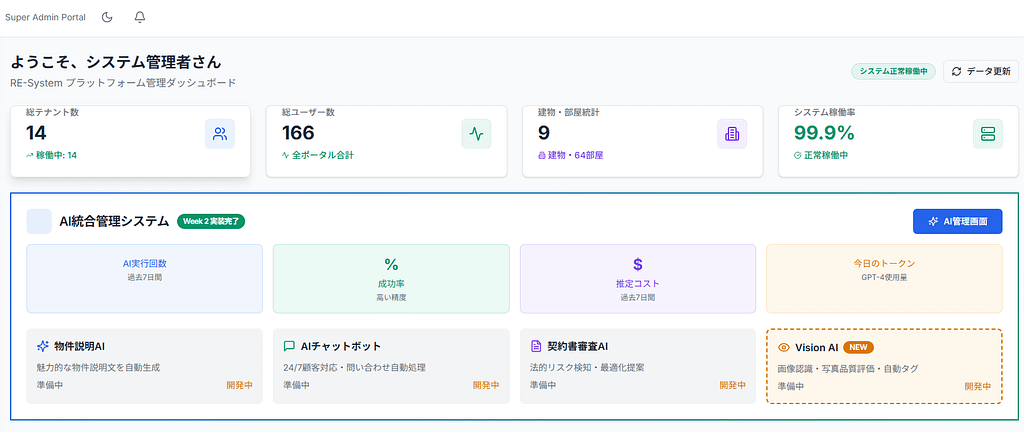
- Super Admin(プラットフォーム管理者向け)
なぜこのプロジェクトを作ったのか
「動いているシステムが実力を証明する」
RE-Systemは、
業務効率化の案件や受託開発のために作ったものではありません。
「自分の技術力を、誰が見ても分かる形で示すため」
その目的だけのために設計・開発されたポートフォリオプロジェクトです。
- 個人開発でも、ここまで作れる
- 設計から運用まで理解している
- 表面的なデモではなく、本番同様の環境で稼働しているシステムである
この3点を重視しています。
実際に稼働している環境
- 本番環境:https://resystem.online
カスタマー:https://yamada.resystem.online/auth/login
テナント管理画面:非公開
パートナー管理画面:非公開
システム管理画面:非公開 - ステージング環境:https://staging.resystem.online
※ 実データを扱うため、管理画面へのログイン情報は公開していません。
このポートフォリオについて
このサイトは、
スキルシートや箇条書きだけでは伝わらない技術力を
「実例」と「構造」で伝えるために作成しています。
もし、
- 個人開発でどこまで作れるのか知りたい
- 実運用を前提とした設計を確認したい
という方がいれば、RE-Systemの構成は参考になるはずです。
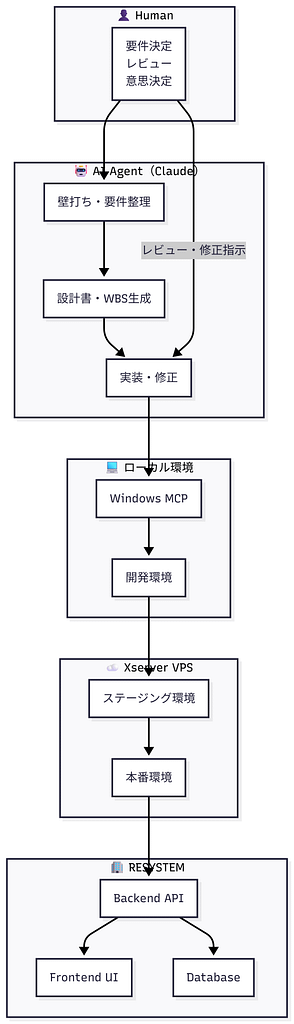
RESYSTEMは、生成AI(Claude)を単なる支援ツールとしてではなく
**「設計・実装を担う自律型AIエージェント」**として組み込んだシステムです。
人間は意思決定・レビュー・品質担保に集中し、
要件定義・WBS作成・実装はAIが主体となって進行します。
本システムはローカル環境で開発され、
ステージング環境を経てXserver VPS上の本番環境で運用されています。
Goal Achiever
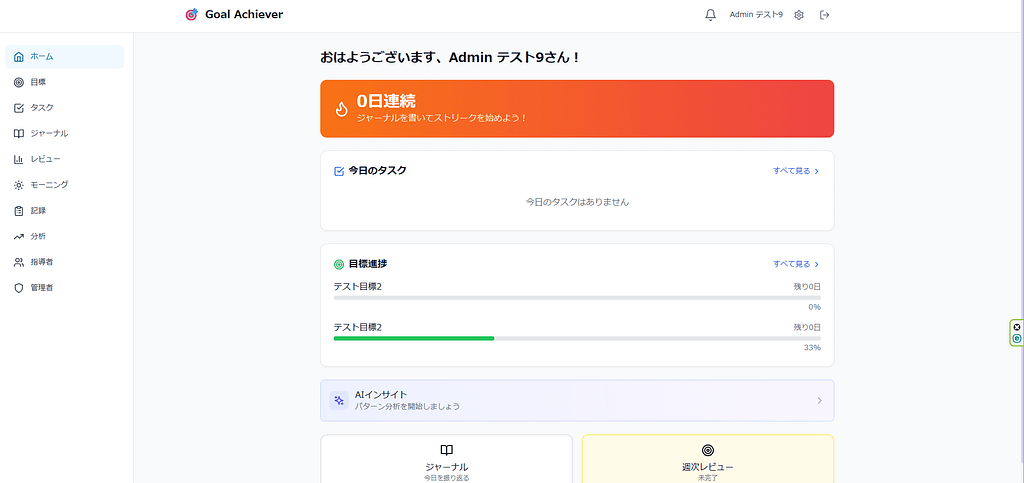
科学的アプローチに基づく目標達成支援Webアプリケーション
URL
https://goal-achiever.ai-creators-hub.com
概要
Goal Achiever は、
目標設定から日々の行動、振り返りまでを一貫して管理する
個人向け目標達成支援アプリケーションです。
SMART目標、習慣形成理論、行動心理学などの
科学的根拠に基づいた設計を取り入れ、
継続的に使われることを重視しています。
開発の目的
- 目標が「立てただけ」で終わる課題を解消したい
- 行動と成果を可視化し、継続を促進したい
- ダッシュボード型UIで状態を直感的に把握できるようにする
主な機能
- 目標・タスク管理
- ダッシュボードによる進捗可視化
- 習慣形成を意識した記録機能
- XP・レベルなどのゲーミフィケーション要素
- 週次・月次レビュー機能
技術構成(要点のみ)
- バックエンド:Laravel(API設計・認証)
- フロントエンド:Vue.js(SPA)
- DB:MariaDB
- インフラ:Xserver 共有サーバー
- 認証:Sanctum
設計・開発で意識した点
- フロントエンドとバックエンドの分離(SPA + API)
- 将来的な機能拡張を前提としたデータ設計
- ローカル → GitHub → 本番 という明確なデプロイフロー
- 個人利用からマルチユーザー展開を想定した構成
担当範囲
- 企画
- 要件定義
- 画面・UX設計
- API設計
- デプロイ・運用
ポートフォリオとしての位置づけ
Goal Achiever は
Webアプリケーションの設計・実装・運用をClaudeを使用して一通り行えることを示すための制作物として開発しています。
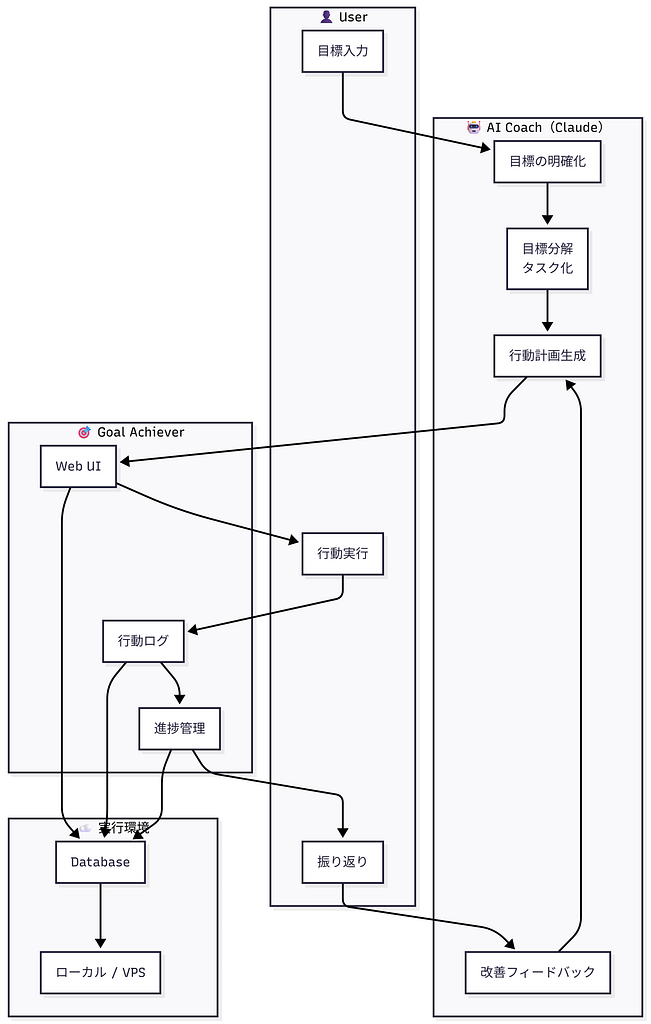
Goal Achieverは、
「目標を立てても続かない」という課題を解決するためのAIコーチ型システムです。
ユーザーが入力した目標をAIが整理・分解し、
行動計画の作成から振り返り・改善提案までを一貫して支援します。
行動ログと進捗データをもとに、
AIが次のアクションを最適化することで、
目標達成までの継続的な伴走を実現しています。
ユーザー行動フロー図
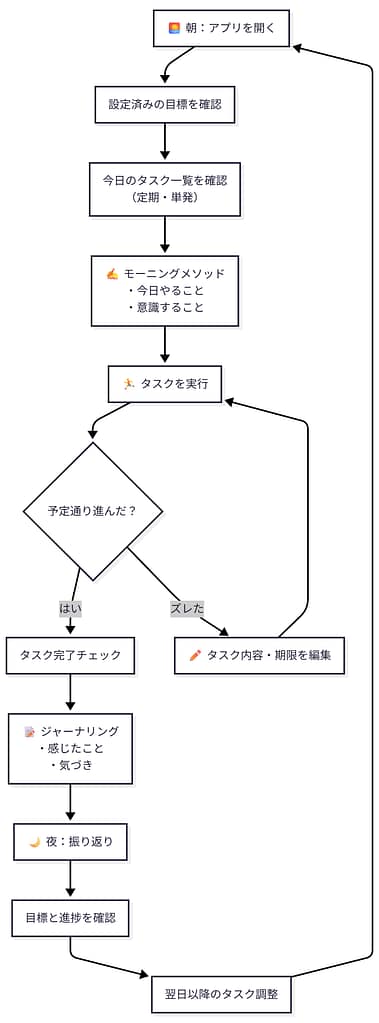
将来構想:AIコーチ全体アーキテクチャ図(概念)
-2026-01-07-082431-787x1024.png)
AIが「やること / やらないこと」
✅ AIがやること(将来)
- 科学的根拠があるフレームワークのみ使用
- 行動ログ・ジャーナルの傾向分析
- 提案のみ(強制しない)
- 継続できる負荷への調整提案
❌ AIがやらないこと
- 根拠のないモチベーション論
- 人格的アドバイス・断定的指示
- 人生判断の代替
- スピリチュアル・自己啓発的表現
科学的アプローチ別・AIの役割整理
①OBLスプリント(Objective Based Learning)
-2026-01-07-082643-1024x160.png)
AIの役割
- Objectiveが曖昧な場合の言語化補助
- タスク粒度が大きすぎる場合の分割提案
- スプリント周期の負荷調整
※ 決定は常にユーザー
②リフレクティブ・ジャーナリング強化
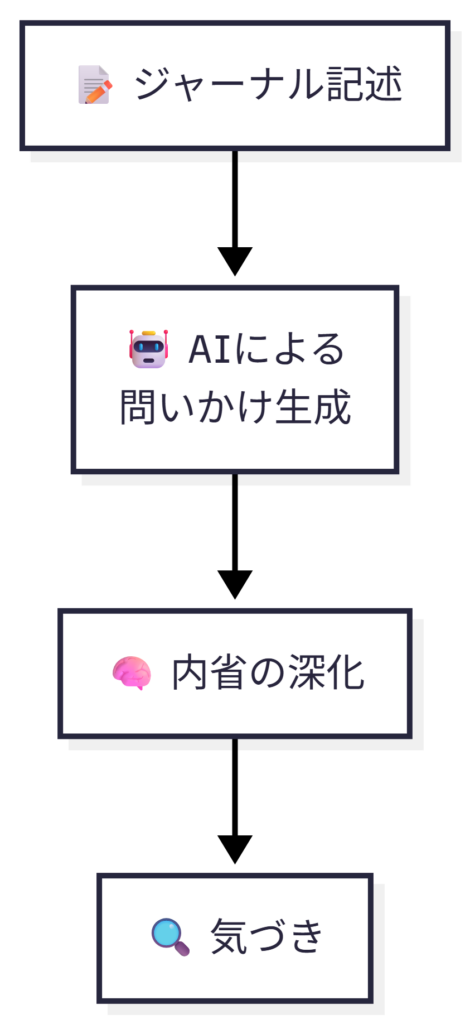
科学的ベース
- メタ認知
- 認知行動療法(CBT)的視点
- 自己効力感の言語化
AIの役割
- 「なぜそう感じたか?」の問いを提示
- 感情と行動の分離をサポート
- 成果・失敗の再解釈支援
③ 継続支援(習慣化サポート)
-2026-01-07-082933-1024x195.png)
AIの判断軸
- 実行率
- 中断頻度
- ジャーナル内の感情傾向
👉
「頑張れ」ではなく
「続く形に調整しよう」 が軸
将来的にGoal Achieverでは、
科学的根拠に基づいたAIコーチ機能の追加を想定しています。
AIは判断主体とはならず、
ユーザーの行動ログ・ジャーナリングをもとに、
目標やタスクの調整案、継続しやすい負荷設計を
提案する補助的存在として設計されます。
OBLスプリントやリフレクティブ・ジャーナリングを強化し、
実行と内省の質を高めることで、
再現性のある行動改善を支援する構想です。
競馬データ収集システム

― 予測可能な意思決定のためのデータ基盤構築 ―
概要
本システムは、競馬情報サイト netkeiba.com からレース・出走馬・騎手・調教師などの情報を継続的に収集・構造化し、
将来的な分析・予測モデル構築を前提としたデータ基盤として設計・開発しました。
単なるスクレイピングではなく、
- データ品質の担保
- 長期運用を前提とした安定性
- 分析用途への拡張性
を重視した設計となっています。
開発背景・動機
社内で競馬が話題になる中、
予想は「山勘」や「オッズ頼り」が中心で、当たっても偶然の域を出ないと感じていました。
そこで、
- 自分なりの再現性あるルールで予想したい
- 感覚ではなく、データに基づいて意思決定したい
という目的から、
「予測できるかどうか以前に、まず信頼できるデータを自分で作る」
という考えで本システムの開発に着手しました。
システムの特徴
1. 分析前提のデータ収集設計
- レース一覧 / 出走表 / 結果 / オッズを分離して取得
- 馬・騎手・調教師といったエンティティを正規化
- 将来的な特徴量生成・分析を想定したデータ構造
単に「取得できるデータ」ではなく、
「使えるデータ」になることを重視しています。
2. データ品質を考慮した実装
開発初期に最も苦労した点は、
- どの程度のデータ量が必要か見当がつかなかったこと
- 欠損値・異常値が非常に多かったこと
です。
そのため、
- スクレイピングは最低0.5秒以上の間隔を確保
- 並列処理はあえて抑制(規約遵守・安定性優先)
- 欠損・異常データを検知するロジックを実装
- 後から補完可能な設計に変更
など、
「速さよりも継続性と信頼性」を優先した設計判断を行いました。
3. 運用フェーズを意識した拡張
本システムは、開発して終わりではなく、
運用を通じて段階的に拡張しています。
後から追加した主な機能
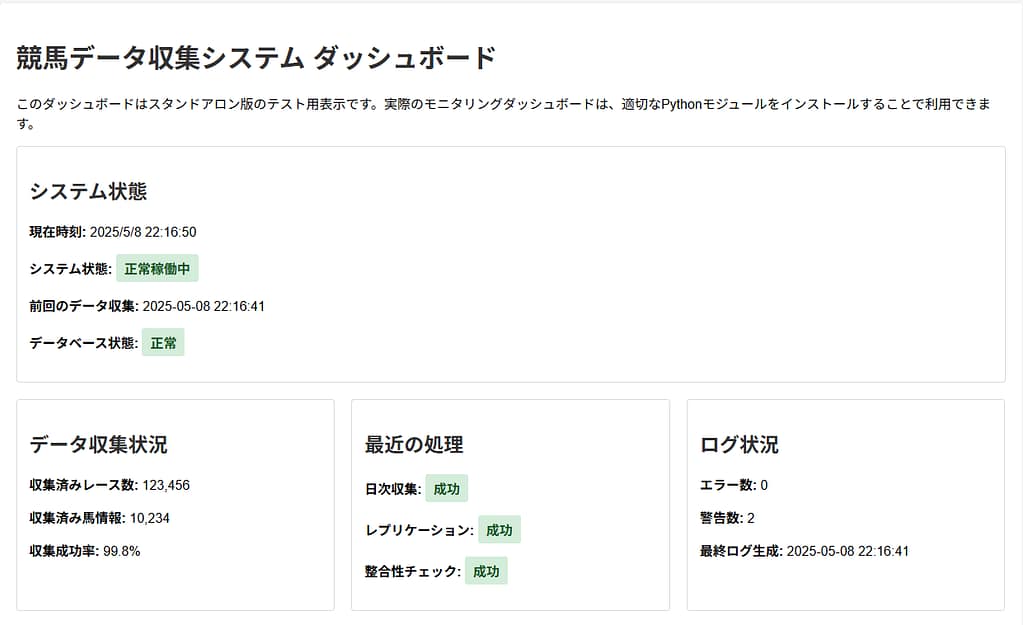
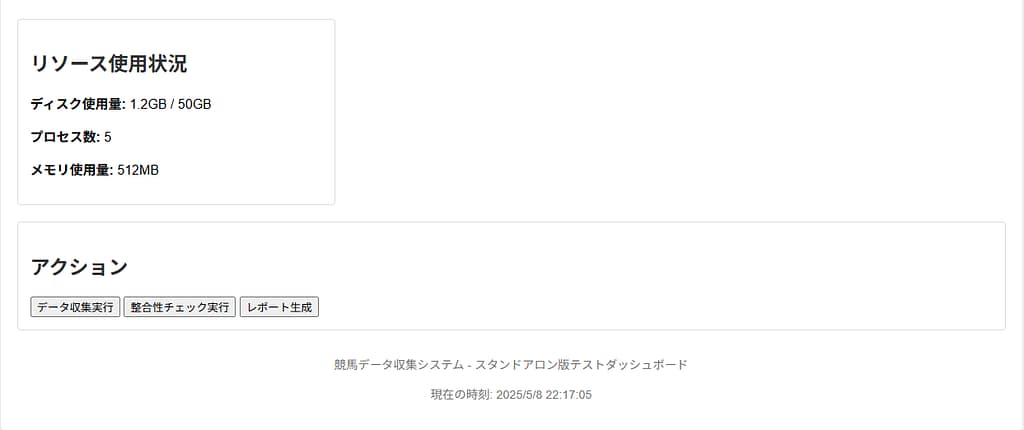
- MySQLレプリケーション(分析用途・負荷分散)
- 稼働状況モニタリングダッシュボード
- データ収集状況の可視化ダッシュボード
- 日次データ収集バッチ
- 欠損データ再取得用バッチ
- 分析用途へのデータ提供(※分析システムは別プロジェクト)
これにより、
- 収集漏れの早期発見
- データ品質の継続的改善
- 分析システムへの安定供給
が可能になりました。
技術スタック
- 言語: Python 3.10
- スクレイピング: Selenium / requests
- HTML解析: BeautifulSoup4
- DB: SQLite(初期) → MySQL(分析用途)
- スケジューリング: バッチ処理(日次)
このシステムで重視したこと
- 規約を守った安全なスクレイピング
- データ量より「品質」を優先する判断
- 運用を通じた改善・拡張
- 分析・予測につなげるための基盤設計
補足
※ 本システムは データ収集・基盤構築 を目的としており、
実際の競馬分析・予測ロジックは別システムとして構築しています。
① 全体アーキテクチャ図(競馬データ収集システム)
-2026-01-07-085944-1024x225.png)
本システムは、レース・出走表・結果・オッズ等の情報を定期的に収集し、
データの正規化・欠損補完・異常値検知を行ったうえでデータベースに蓄積します。
日次バッチおよび欠損補完バッチを分離することで、
長期運用を前提とした安定したデータ収集と再実行性 を確保しています。
また、分析用途としてMySQLへデータを連携し、
稼働状況やエラーを監視するモニタリング機構も実装しています。
データフロー図(収集 → 正規化 → 保存)
-2026-01-07-085944-1024x225.png)
運用・監視構成図(安定稼働・継続運用)
-2026-01-07-090545-730x1024.png)
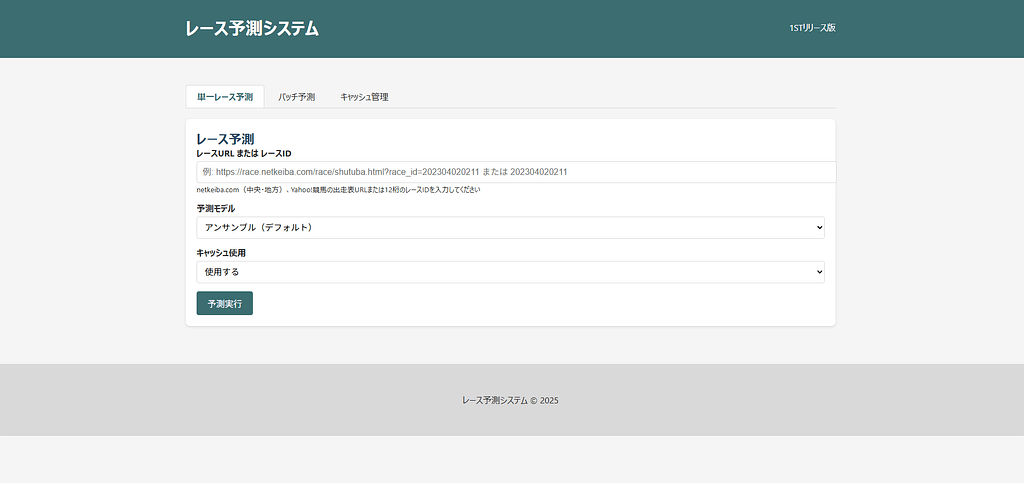
競馬予測システム
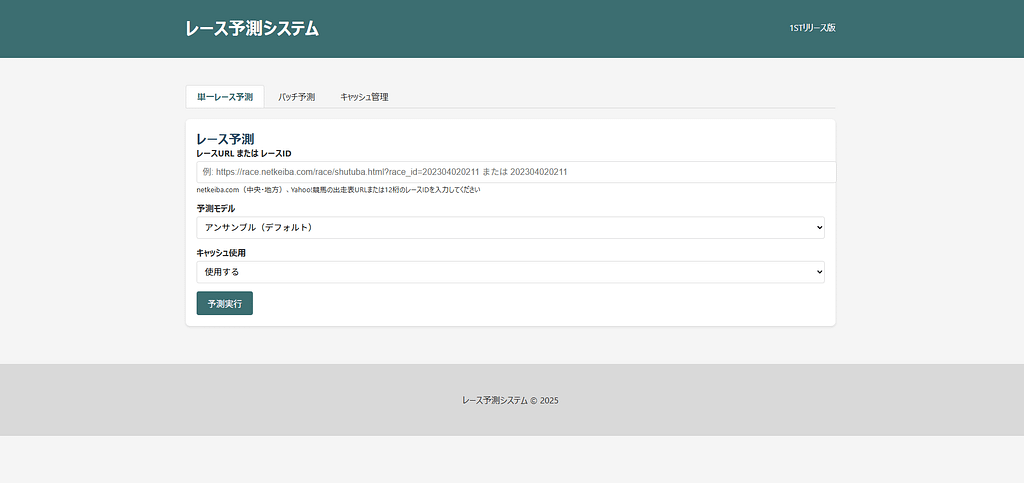
― データ基盤から機械学習までを一貫設計したレース予測エンジン ―
概要
本システムは、
自作の競馬データ収集基盤を入力として、機械学習を用いてレース結果を予測するシステムです。
単なるモデル構築ではなく、
- データ収集〜前処理〜特徴量設計
- 複数モデルによる予測・評価
- API / UI 提供
- 将来的な拡張を見据えた設計
までを一貫して行っています。
開発背景・目的
競馬データ収集システムを構築する中で、
「データは集まったが、どう使えば“再現性のある予測”になるのか?」
という課題に直面しました。
- 単一モデルでは限界がある
- コース・競馬場特性を無視すると精度が安定しない
- 特徴量設計次第で結果が大きく変わる
これらを踏まえ、
「分析ありき」ではなく「運用可能な予測システム」
として設計したのが本システムです。
システムの特徴
1. データ前提を疑う設計思想
本システムでは、
「モデルよりも、前段のデータと特徴量が重要」
という考えを重視しています。
- 2018年以降の全レースデータを対象
- 中央競馬・地方競馬の両方に対応
- 欠損・表記揺れ・異常値を前提に設計
特に馬体重データ(例: 480(0))など、
実データ特有の問題に対応するため、
前処理専用ロジックを実装しています。
2. 段階的リリースを前提とした設計
いきなり「全部入り」を目指さず、
段階的に精度を高めるロードマップを設計しました。
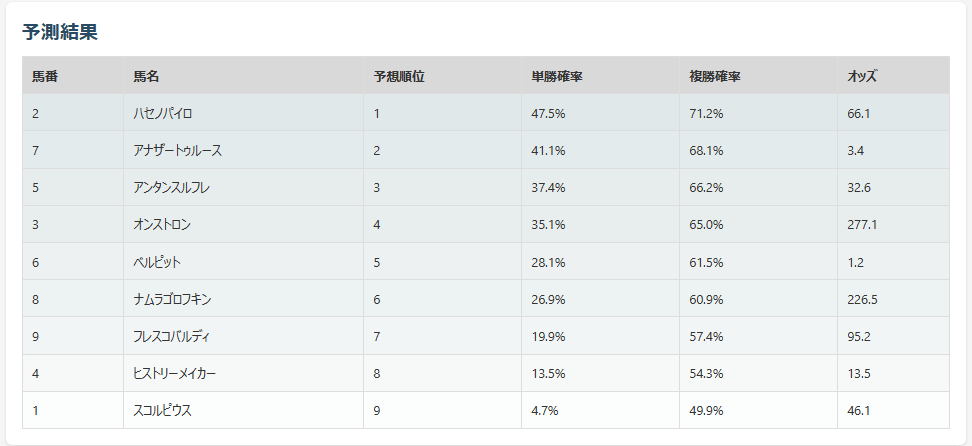
1STリリース(現在)
- 出走表情報
- 過去レース結果
- 馬番ベース特徴量
- 基本モデルによる予測
2ND / 3RDリリース(予定)
- 馬・騎手・調教師データ
- 血統情報
- 時系列・成長曲線分析
- 高度アンサンブルモデル
これにより、
「動くものを先に作り、改善し続ける」
開発スタイルを実践しています。
3. 複数モデル+アンサンブル構成
単一モデルに依存せず、
以下のモデルを用途に応じて使い分けています。
- LightGBM
- XGBoost
- Random Forest
- ディープラーニング(試験導入)
- アンサンブルモデル
また、
- 芝 / ダート
- 競馬場別特性
を考慮したモデル設計を行い、
「どのモデルを使うか」も戦略の一部として扱っています。
4. API・UI・CLIを備えた実運用志向
研究用コードに留めず、
「使えるシステム」としての形を意識しています。
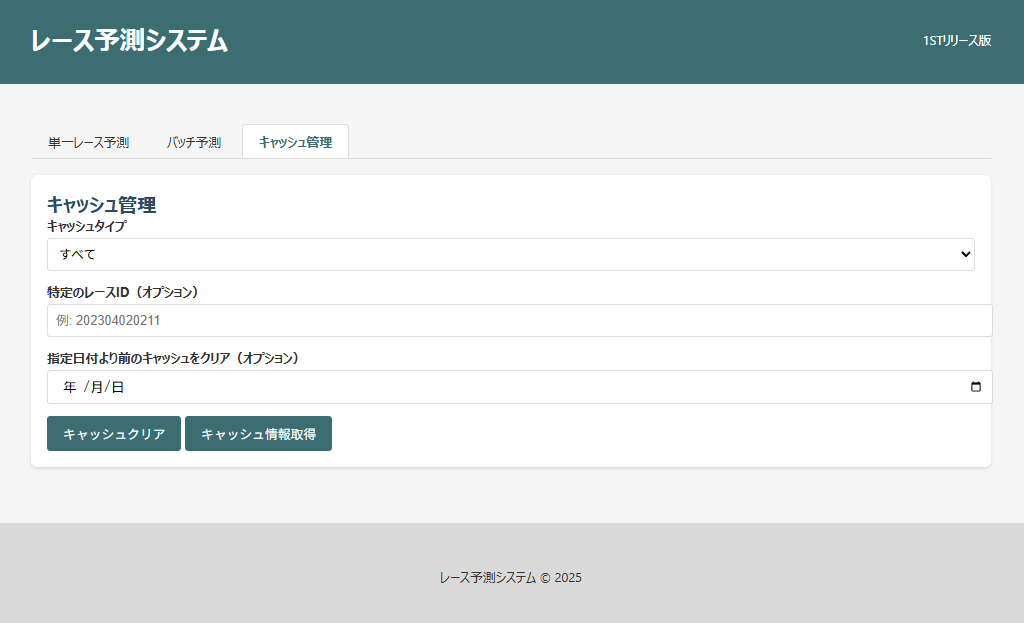
- FastAPIによるWeb API提供
- レースID / URL入力からの即時予測
- バッチ予測対応
- シンプルなWeb UI
- CLIからの実行にも対応
これにより、
- 他システム連携
- 自動化
- 運用時の再利用
が可能になっています。
技術スタック
- 言語: Python 3.10
- 機械学習: LightGBM / XGBoost / scikit-learn
- データ処理: pandas / numpy
- API: FastAPI
- DB: MySQL
- 監視: Prometheus / Grafana
- 実行環境: Docker / Docker Compose
開発で直面した課題と対応
課題1:実データ特有の表記揺れ・欠損
- 馬体重・成績データの形式が不統一
- → 専用パーサ・前処理ロジックを実装
課題2:テストが破綻する問題
- 初期テスト設計と実装の乖離
- → pytest設定の見直し、対象テストの整理
課題3:精度より「安定性」
- 一部レースでは高精度でも、全体では不安定
- → アンサンブル+条件別モデルへ移行
このシステムで重視したこと
- 「当たるか」より「改善できるか」
- モデル精度だけでなく、前処理・設計の重要性
- 将来拡張を前提とした構造
- 運用・再利用可能な形に落とし込むこと
補足
※ 本システムは 研究用途ではなく、実運用を想定した設計 を行っています。
※ 投票戦略・回収率最適化については、今後の拡張対象としています。
特徴量生成フロー図(Feature Engineering)
-2026-01-07-090829-885x1024.png)
学習・推論分離アーキテクチャ図
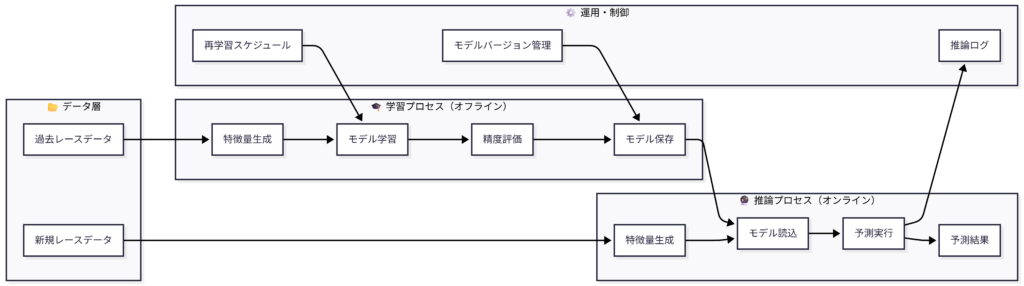
システム全体の運用フロー図
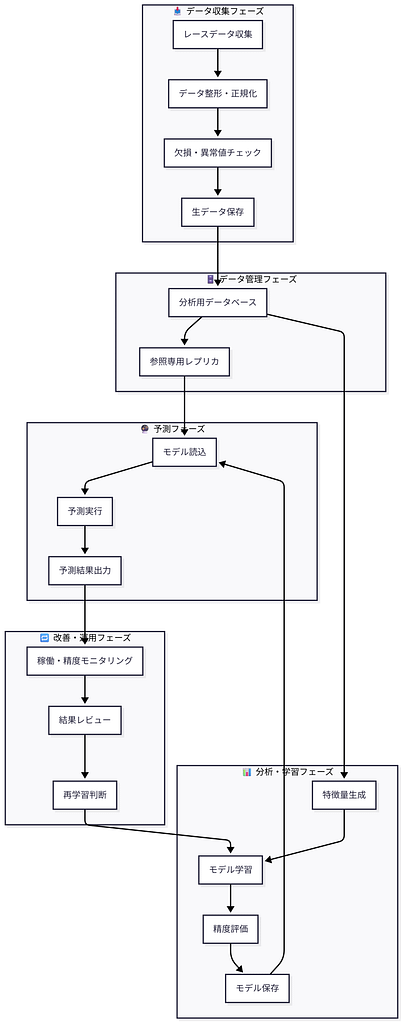
設計判断・制約対応・工夫点 可視化図
開発フェーズ進化図(Before → After)
-2026-01-07-091552-1024x396.png)
高品質動画アップスケーラー
― AIと画像処理を組み合わせた実用志向の動画高画質化システム ―
概要
本システムは、
低解像度・低フレームレートの動画を高品質化するデスクトップアプリケーションです。
AI技術と従来の画像処理アルゴリズムを組み合わせ、
- 解像度の向上(アップスケーリング)
- フレームレートの向上(フレーム補間)
- ノイズ除去
- 色調補正
- 高品質な動画再構築
を GUI操作で一貫して実行 できる設計としています。
開発背景・目的
生成AIや動画生成技術の進化により、
- 昔の映像資産
- 低品質なキャプチャ動画
- AI生成動画の粗さ
といった 「素材の質の問題」 を後処理で改善する需要が増えていると感じました。
一方で、
- CLIツールは敷居が高い
- 処理手順が分断されがち
- モデル依存で環境構築が難しい
という課題も多く、
「非エンジニアでも使える高品質動画処理ツール」 を目標に開発しました。
システムの特徴
1. パイプライン型アーキテクチャ
本システムは、
動画処理を段階的なパイプラインとして設計しています。
入力動画
→ ノイズ除去
→ フレーム抽出
→ アップスケール
→ 色調整
→ フレーム補間
→ 動画再構築
→ 出力動画
各処理ステップは 独立したモジュール として実装されており、
- 個別の改善・差し替え
- 新アルゴリズムの追加
- AIモデルの置き換え
が容易な構成になっています。
2. AIフレーム補間(RIFE)の統合
単純な線形補間ではなく、
RIFE(Recurring Flow-based Frame Interpolation) を統合しています。
- 動きの多いシーンでも自然な中間フレーム生成
- 高フレームレート化による滑らかな映像表現
- GPU環境では高速推論が可能
UI上ではチェックボックス操作のみで有効化でき、
高度なAI処理を意識せず利用可能です。
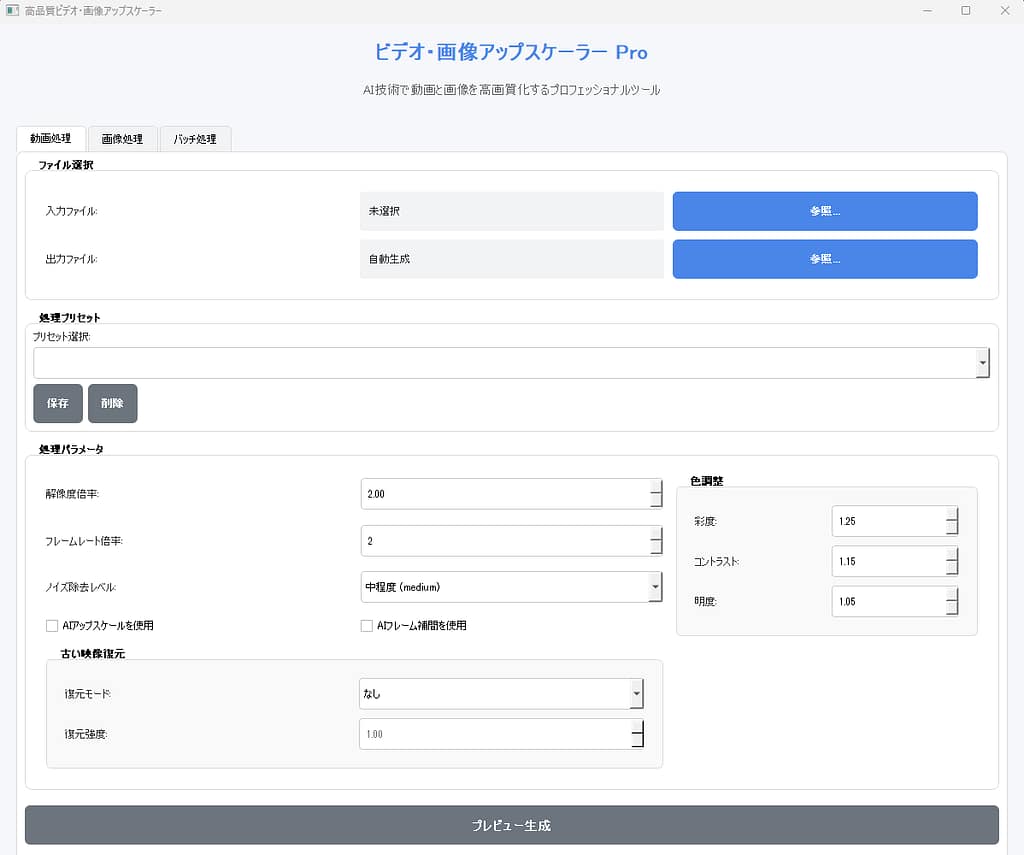
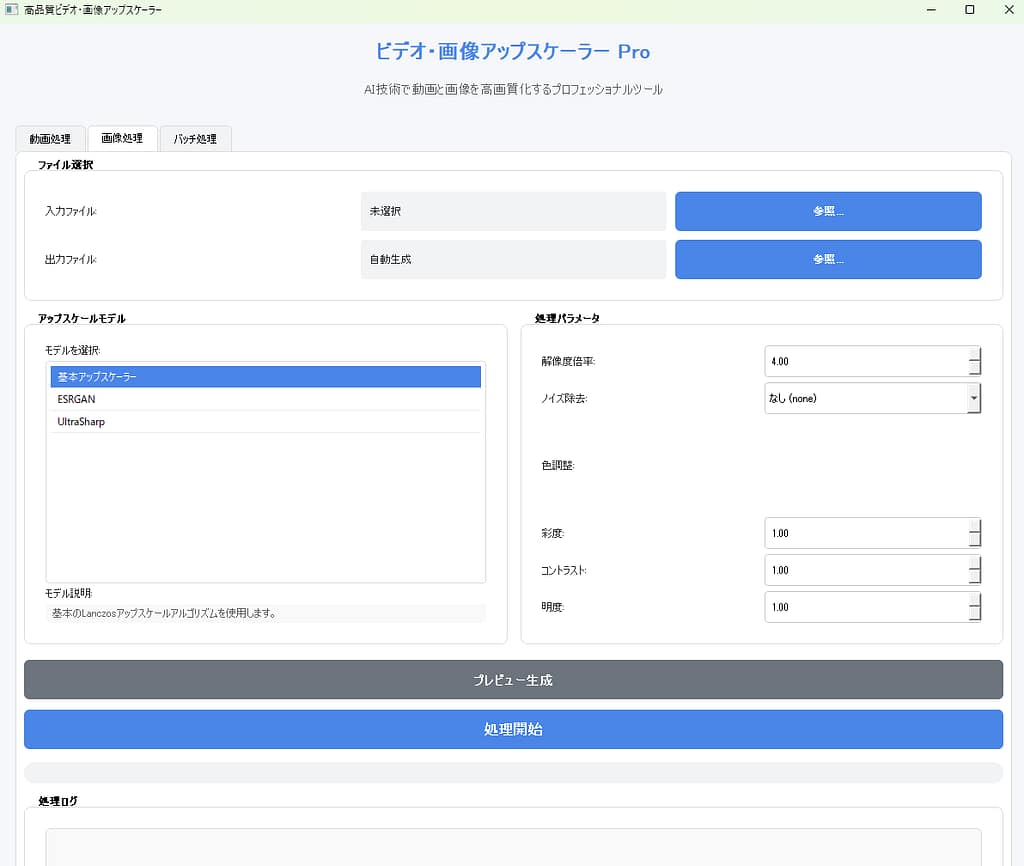
3. GUI重視のユーザー体験設計
PyQt5を用いたデスクトップGUIを実装し、
- 入力動画の選択
- パラメータ設定
- 処理進捗の可視化
- ログのリアルタイム表示
を一画面で完結できる設計にしています。
また、
- UIは非同期処理
- 長時間処理でもUIはブロックしない
といった 実運用を意識したUX を重視しました。
4. プリセット・プレビュー機能による実用性
プリセット管理
用途別に設定を保存・再利用できます。
- アニメ向け
- 実写向け
- 古い映像向け
これにより、毎回の細かい調整を不要にしています。
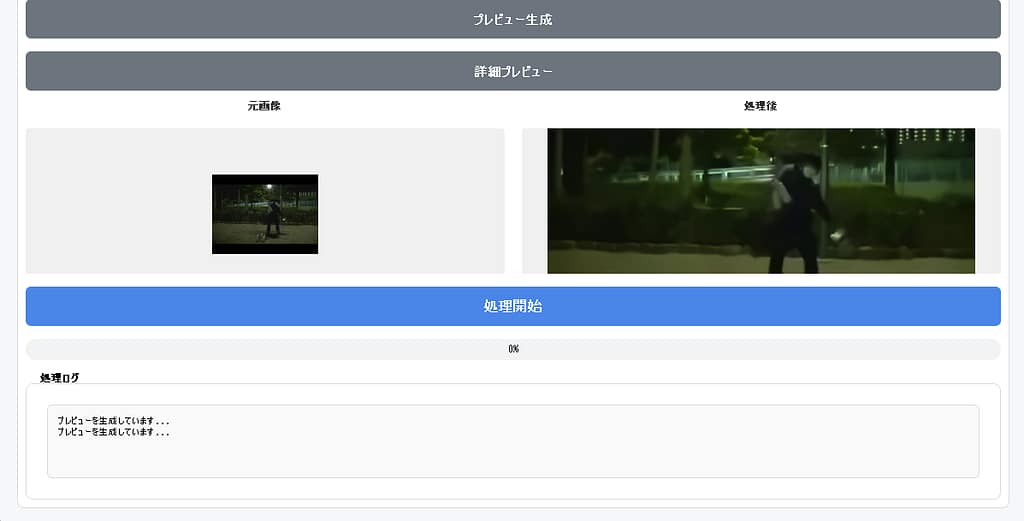
詳細プレビュー
処理前後の比較を以下の方法で確認可能です。
- 並列表示
- 分割表示
- スライド比較
- ズーム・パン操作
品質確認を行った上で処理を進められる設計です。
技術スタック
- 言語: Python 3.x
- GUI: PyQt5
- 動画処理: FFmpeg
- 画像処理: OpenCV / NumPy
- AI推論: PyTorch(RIFE)
- GPU対応: CUDA(環境対応時)
開発で苦労した点
1. メモリ・リソース管理
- 高解像度動画はフレーム単位でもメモリ消費が大きい
- → 一時ファイル管理と段階処理で解決
2. UIと重い処理の両立
- 処理が重いとUIが固まる問題
- → マルチスレッド化で対応
3. 品質と速度のトレードオフ
- 高品質=処理時間が長くなる
- → プリセットとパラメータ調整でユーザーに選択肢を提供
設計で重視したこと
- 「研究用コード」で終わらせない
- GUI・操作性・エラー回復を含めた「製品視点」
- AIと従来技術の適材適所な使い分け
- 将来のモデル差し替えを前提とした設計
今後の拡張予定
- Real-ESRGAN 等の高精度アップスケーラー統合
- モデル選択機能
- 顔認識による重点補正
- バッチ処理機能の強化
- プレビュー機能のさらなる高度化
全体処理フロー図

本システムは、低解像度動画を一度フレーム単位に分解し、
AIによるアップスケール処理と補正処理を行った後、
再度動画として再構成するパイプライン構造を採用しています。
単純な解像度拡大ではなく、
ノイズ低減やディテール補完を行うことで、
視覚的品質の向上を重視しています。
システム構成図(GPU・実行環境)
-2026-01-07-092120-1024x1004.png)
Dead by Daylight Perk Selection System

― モバイルファーストで設計した意思決定支援Webアプリ ―

概要
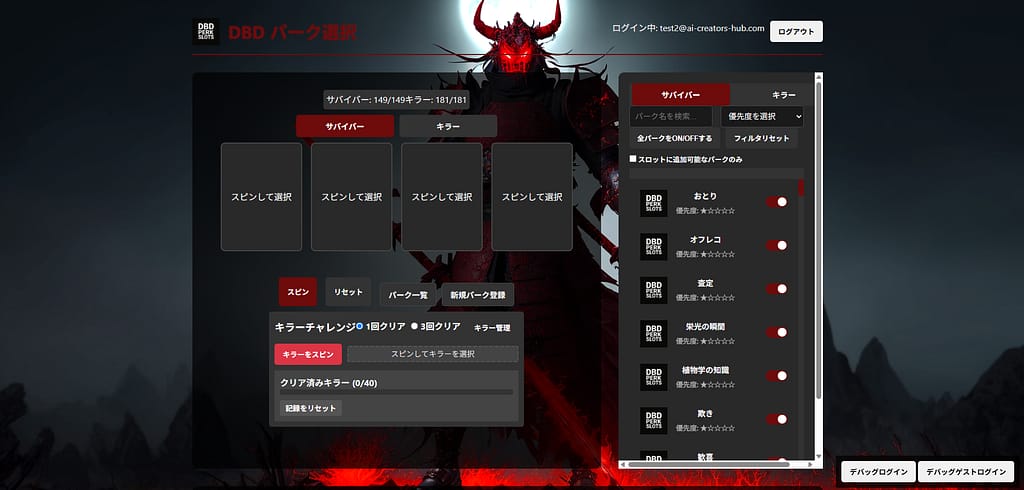
Dead by Daylight Perk Selection Systemは、
Dead by Daylightのパーク選択を効率化・多様化するWebアプリケーションです。
プレイヤーがゲーム開始前に行う
- パーク構成の検討
- ランダム構成の生成
- 使用パークの管理
といった意思決定を、
モバイル環境でも快適に行えることを最優先に設計しています。
開発背景・動機
Dead by Daylightでは、パーク構成がプレイ体験に大きく影響しますが、
- いつも同じ構成になってしまう
- パーク数が多く、選択に時間がかかる
- ランダム構成を楽しみたいが手動では面倒
といった課題を感じていました。
特に、
- スマートフォンでゲーム準備をするユーザー
- プレイ前に短時間で構成を決めたいユーザー
にとって使いやすいツールが少なかったため、
**「モバイルファーストの意思決定支援ツール」**として本システムを開発しました。
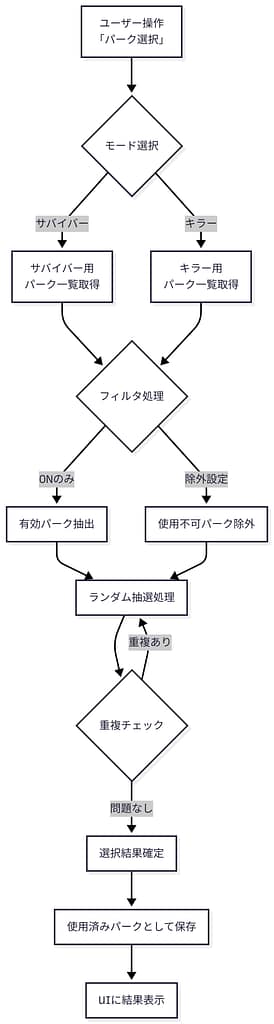
システムの特徴
1. スロットマシン形式のパーク選択
単なるランダム抽選ではなく、
- 視覚的に楽しい
- 直感的に結果が理解できる
スロットマシン形式のUIを採用しています。
これにより、
- 構成を考える時間そのものを楽しめる
- プレイのマンネリ化を防げる
という体験を提供しています。
2. サバイバー/キラー別のパーク管理
ゲーム仕様に合わせて、
- サバイバー用パーク
- キラー用パーク
を 完全に分離して管理しています。
また、
- 使用済みパークの自動除外
- 有効/無効の切り替え
- 一括On / Off
など、実プレイに即した管理機能を実装しています。
3. モバイルファーストUI設計
本システムは 最初からスマートフォン利用を前提に設計されています。
- タッチ操作前提のUI
- 片手操作でも完結するレイアウト
- モーダル・フィルタ操作の最適化
デスクトップ対応は行いつつも、
主戦場はモバイルという明確な設計方針を取っています。
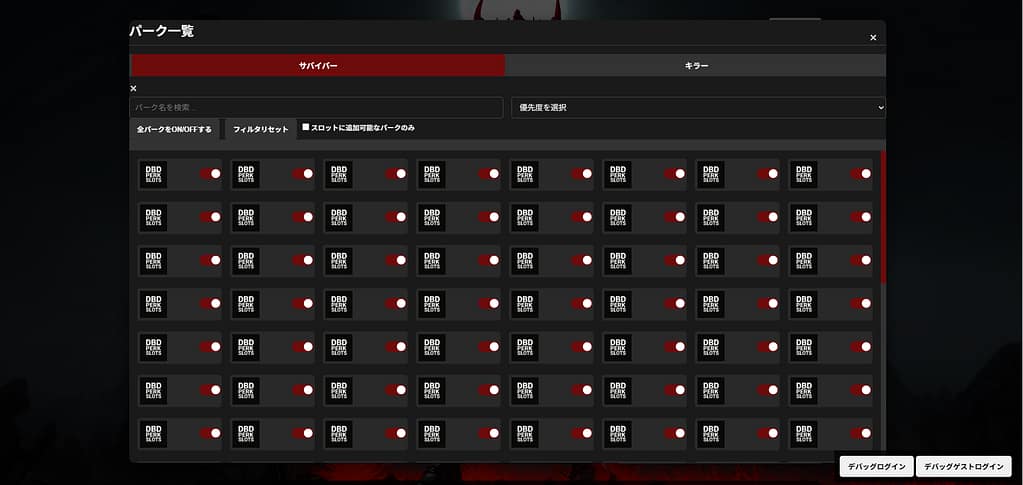
4. 柔軟なパーク管理・フィルタリング
パーク数増加を前提に、以下の機能を実装しています。
- カテゴリー別フィルタ
- 優先度フィルタ
- アクティブ/非アクティブ切り替え
- JSONファイルからのパークデータ取り込み
これにより、
- ゲームアップデートによるパーク追加
- ユーザー独自ルールでの拡張
にも柔軟に対応可能です。
ユーザー認証・データ管理
認証機能
- Firebase Authenticationを使用
- メールログイン
- ゲストログイン対応
データ管理
- Firebase Realtime Database
- ユーザーごとのパーク設定保持
- リアルタイム更新対応
アカウント作成のハードルを下げつつ、継続利用を可能にする設計です。
技術スタック
- フロントエンド: JavaScript(モジュール構成)
- UI設計: モバイルファースト / レスポンシブ
- バックエンド: Firebase Realtime Database
- 認証: Firebase Authentication
- データ管理: JSONベースの拡張設計
開発で重視したポイント
1. ゲーム理解を前提とした設計
- 単なる技術デモではなく、実プレイに即した仕様
- サバイバー/キラー分離などゲーム文脈を反映
2. 操作回数の最小化
- 何タップで目的を達成できるかを常に意識
- モバイル操作時のストレスを徹底排除
3. 拡張前提の設計
- パーク数増加
- フィルタ条件追加
- コミュニティ機能追加
を想定した構成にしています。
想定される活用シーン
- 外出先・移動中にパーク構成を考える
- フレンドとランダム構成で遊ぶ
- マンネリ打破のための縛りプレイ
- 新パークの試用
今後の拡張構想
- パーク構成の共有機能
- コミュニティ投稿・評価
- プレイ傾向の統計分析
- カスタムルール生成
- AIによる構成提案
全体システム構成図
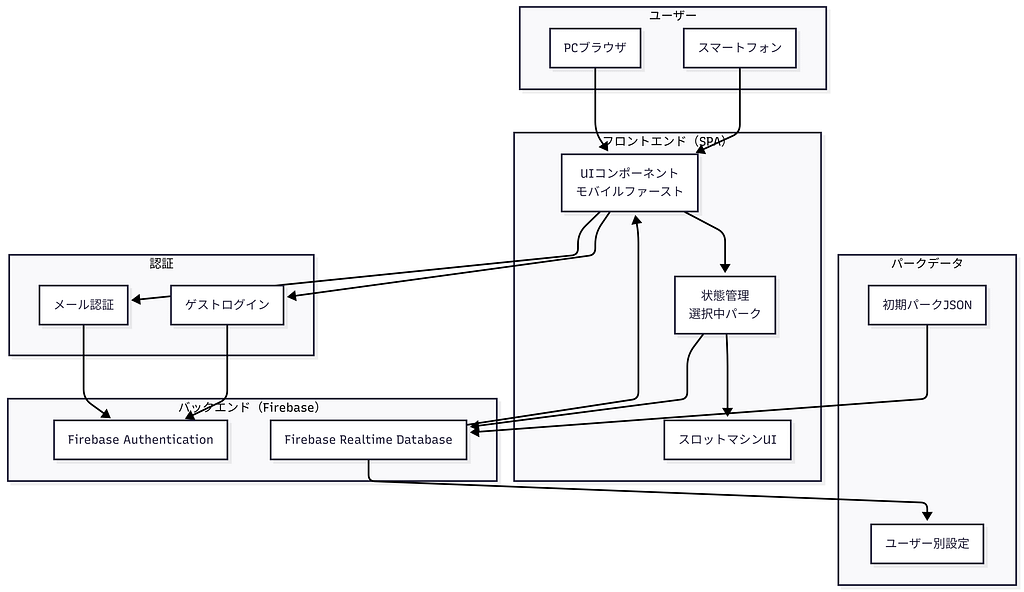
本システムは、モバイル利用を前提としたSPA構成のWebアプリです。
フロントエンドで状態管理を行い、
Firebase Authentication による認証と
Firebase Realtime Database によるユーザー別パーク設定の永続化を行っています。
パーク選択はスロットマシン形式のUIで提供し、
ランダム性と操作性の両立を実現しています。
WordPress Blog Automation System
― 生成AI×WordPress 自動記事公開基盤 ―

概要
生成AI(Claude)で作成した記事コンテンツを、
SEO設定・画像処理・テーマ固有設定まで含めて
WordPressへ自動投稿するための業務自動化システム。
単なる記事投稿に留まらず、
「実運用で使えるブログ公開フロー」 を目的として設計・開発。
このシステムを作った動機
- 生成AIで記事作成は可能になったが
WordPress側の設定が結局手作業になる - SEO設定、タグ、テーマ依存項目がボトルネック
- 大量記事運用では「人が触る工程」が最大の非効率
そこで
「AIが作った記事を、人が触らずに“公開できる状態”まで持っていく」
ことを目的に開発を開始。
■ システムの特徴
1. 生成AI前提の設計
- Claudeが生成する
- 記事本文(Markdown)
- メタデータ(SEO / タグ / カテゴリ / SNS文)
- 2ファイル構成を前提に処理フローを設計
👉 生成AIとの役割分担が明確
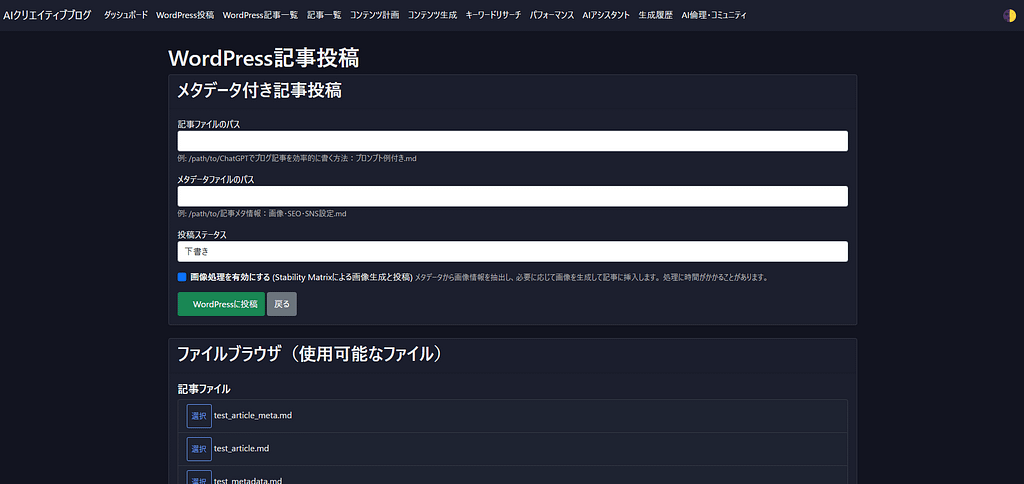
2. WordPress実運用に耐える投稿フロー
WordPress投稿を あえて1リクエストで完結させない設計。
- 記事本文・タイトル投稿
- タグ設定(ID変換を考慮)
- RankMath SEO設定(専用API)
- テーマ固有SEO設定(JIN対応)
👉 安定性を最優先したマルチステップ処理
3. マークダウン変換を“しない”という判断
- マークダウン → HTML変換を想定していたが
- 実検証により
WordPressはマークダウン直投稿で問題ない と判断
👉 不要な変換処理を排除し、保守性を向上
4. 画像処理・アイキャッチ自動化(設計・実装中)
- 記事内画像参照を検出
- WordPressメディアライブラリへ自動アップロード
- 記事内URL置換
- メタデータ指定によるアイキャッチ自動設定
技術構成
バックエンド
- Python
- Flask
- SQLAlchemy / SQLite
- WordPress REST API
- Rank Math SEO API
設計思想
- 機能分離されたモジュール設計
- テスト前提(Unit / Integration / E2E)
- 生成AIとの協調を前提としたワークフロー設計
■ 苦労した点・工夫した点
- WordPress REST APIの制約
- RankMath SEOのAPI仕様の癖
- テーマ固有フィールドの更新制限
- マークダウン投稿の実検証
- 650〜1300行クラスの長文記事テスト
👉 「動く」ではなく「運用できる」ラインまで落とし込んだ
■ 将来的な拡張
- 完全自動スケジューリング
- 複数ブログ同時投稿
- 内部リンク自動最適化
- AIによるリライト・再投稿
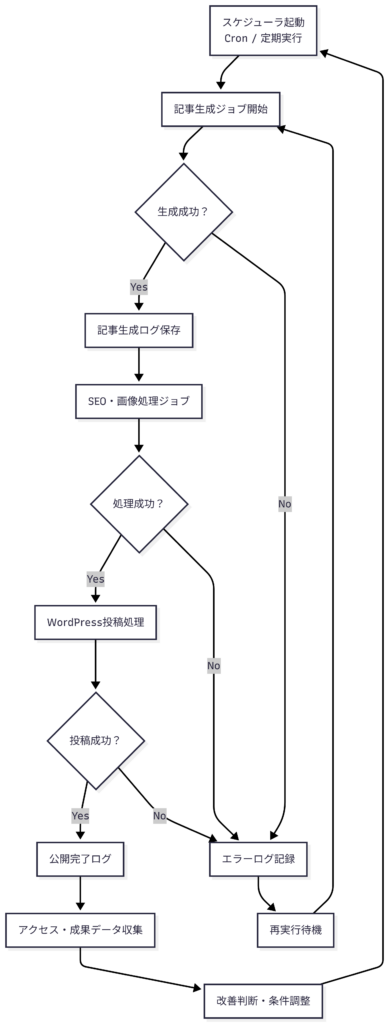
全体アーキテクチャ図

公開ワークフロー図
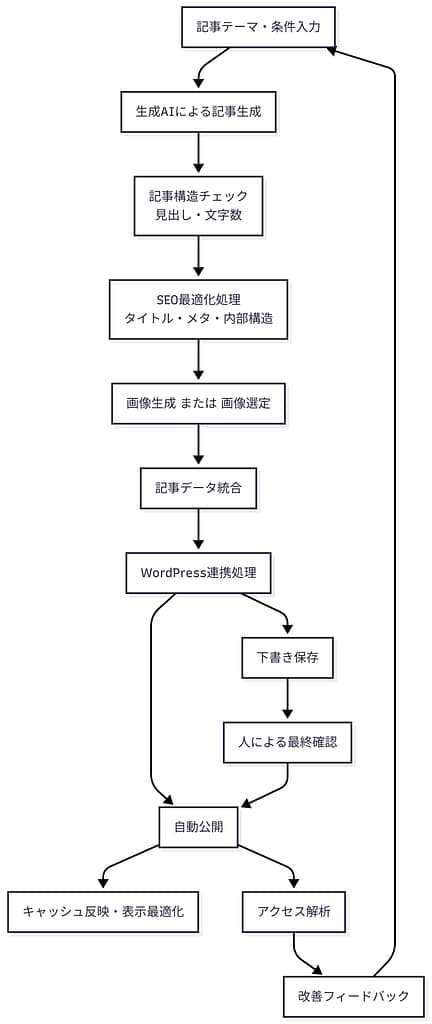
運用・自動化フロー図